🔥 Our paper collection is now available at GitHub
 !
!
Introduction
In recent years, remarkable progress has been witnessed in large language models (LLMS) , which have achieved excellent performance on various natural language processing tasks. In addition, LLMs raise surprising emergent capabilities, including in-context learning, chain-of-thought reasoning and even planning. Nevertheless, the majority of LLMs are English-Centric LLMs that mainly focus on the English tasks, which still slightly weak for multilingual setting, especially in low-resource scenarios.
Actually, there are over 7000 languages in the world. With the acceleration of globalization, the success of large language models should consider to serve diverse countries and languages. To this end, multilingual large language models (MLLM) possess the advantage when handling multiple languages, gaining increasing attention.
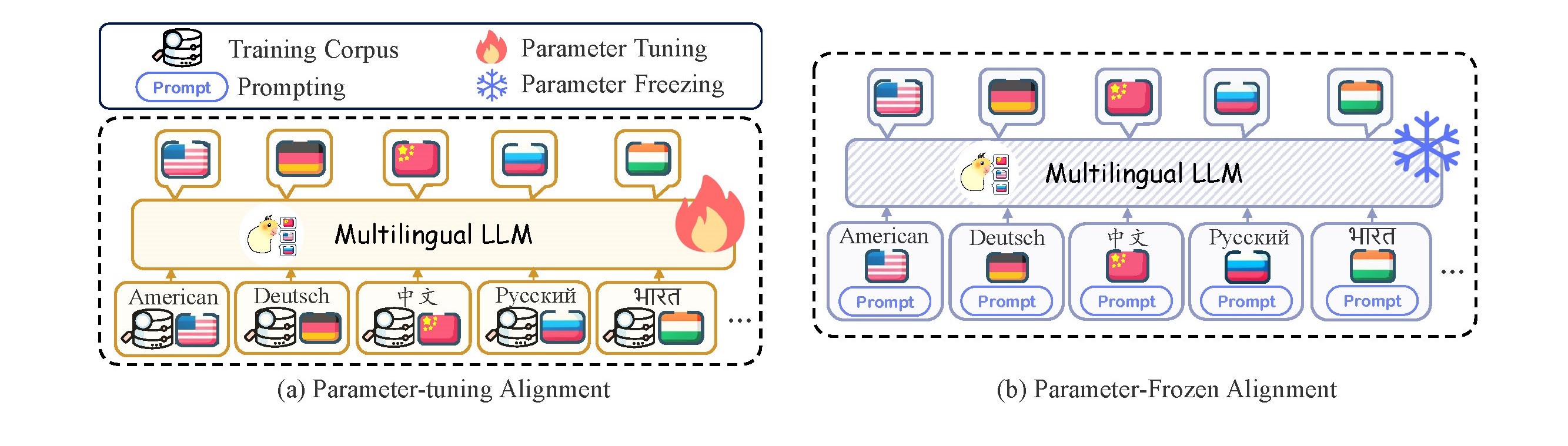
The existing MLLMs can be divided into three groups based on different stages. The first series of work leverage large amounts of multilingual data in the pre-training state to boost the overall multilingual performance. The second series of work focus on incorporating multilingual data during supervised fine-tuning (SFT) stage. The third series of work also adapt the advanced prompting strategies to unlock deeper multilingual potential of MLLM during parameter-frozen inference.
While promising performance have been witnessed in the MLLM, there still remains a lack of a comprehensive review and analysis of recent efforts in the literature, which hinder the development of MLLMs. To bridge this gap, we make the first attempt to conduct a comprehensive and detailed analysis for MLLMs. Specifically, we first introduce the widely used data resource, and in order to provide a unified perspective for understanding MLLM efforts in the literature , we introduce a novel taxonomy focusing on alignment strategies including
- parameter-tuning alignment
- parameter-frozen alignment
In the following are two categories for aligning method:
If you find this repository helpful for your work, please kindly cite the following paper.
@misc{qin2024multilingual,
title={Multilingual Large Language Model: A Survey of Resources, Taxonomy and Frontiers},
author={Libo Qin and Qiguang Chen and Yuhang Zhou and Zhi Chen and Yinghui Li and Lizi Liao and Min Li and Wanxiang Che and Philip S. Yu},
year={2024},
eprint={2404.04925},
archivePrefix={arXiv},
primaryClass={cs.CL}
}